Handling Audio Data
Posted on Wed 12 September 2018 in machine_learning
Preface¶
Previously, I have only ever handled structured tabular data. Examples being the iris data or the spinal data which have already been given labels and put in a nice and neat csv. Working with that sort of data has its own value, but the mass majority of data collected in the world is unstructured in a form that is not easily interpretable by humans or machine.
With that said, today's blog will be going over how to handle one of the most abundant forms of unstructured data, audio. This is a necessary first step before moving any further with my audio-based ML ideas.
What is Audio Data?¶
We know that audio is all around us and is interpreted by our brain's constantly. But audio to a computer is less continuous and perfect than what we hear. Certain devices (ie microphones) capture the sounds and converts them to a wave-like format where the amplitude changes over time.
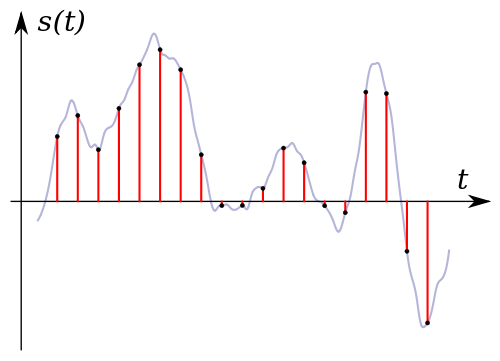
The device captures the value of the wave signal repeatedly and stores it as a number(in bytes). The 2 factors that can be adjusted for this is the sampling rate#Sampling_rate)(Hz, how many measurements taken per second) and how fine-tuned the measurements are. Typically they are 2-byte values giving it a value range from [-32768, 32767]. That is then used to recreate the original data, which will always theoretically fall short of the original, but it may or may not seem any different to our ears.
There are various file formats the audio can be stored as, but the most true to form format is the WAV file. This audio file is one that uses no sort of lossy compression, stores the raw data that is captured from the audio recorder. This results in a higher quality audio at the price of a large file size. This was an isssue when people wanted to put an entire album onto a CD. In that case they used other formats that used lossy compression, such as MP3. At the cost of some audio quality, they are able to greatly reduce the file size.
Librosa¶
When searching for the best python library to process audio data, I found Librosa. This is a library that purely handles audio and music processing.
Librosa handles the audio signal as a one-dimensional numpy array. It is a denoted as y and is accompanied by sr which is the sampling rate(if you remember, that is the frequency in Hz). You may be wondering how it handles stereo audio. By default, the load function will downmix the audio to mono by averaging the left and right channels and then resamples the monophonic signal to the default rate sr=22050 Hz. For more info check out the librosa paper.
Setup¶
To get librosa up and running, I simply ran "pip install librosa" in the cmd line (requires you to have python and pip installed). For other methods of installation, you can view their github documentation.
After that I ran into an issue with reading in an audio file[backend error] and it had to do with a codec error, which required me to download ffmpeg to resolve. You also need to be sure to add the ffmpeg bin folder as an environment variable so that python can find it. Then you must restart any cmd line you are using, including a currently running jupyter notebook session for it to take effect.
Imports¶
import librosa # For audio processing
import IPython.display # For displaying audio
import matplotlib.pyplot as plt # For any plotting
import numpy # Math operations
import warnings; warnings.simplefilter('ignore') # To hide warnings from notebook
Load Drum Audio¶
The librosa.load() function returns a 1D np.array that contains all the signal values that were captured during sampling(drum_signal). It also returns the sample rate (sr1).
# Load drum file
drum_signal, sr1 = librosa.load('../audio/drums.wav')
print("Amount of samples contained in the signal: {}".format(len(drum_signal)))
print("Length of the drum track in seconds (length of drum_signal/sample_rate): {}".format(len(drum_signal)/sr1))
Drum Waveplot¶
import librosa.display
librosa.display.waveplot(drum_signal, sr=sr1)

Drum Track Audio¶
As you could assume, increasing the sampling rate will cause the song to speed up and lowering it will cause it to slow down.
IPython.display.Audio(drum_signal,rate=sr1)
Load Guitar Audio¶
# Load guitar file
guitar_signal, sr2 = librosa.load('../audio/guitar.wav')
print("Amount of samples contained in the guitar signal: {}".format(len(guitar_signal)))
print("Length of guitar track in seconds: {:.2f}".format(len(guitar_signal)/sr2))
# Reduce the guitar to same length as drum track
guitar_signal = guitar_signal[:len(drum_signal)]
print("Amount of samples contained in the guitar signal after reduction: {}".format(len(guitar_signal)))
print("Length of guitar track in seconds after signal reduction: {:.2f}".format(len(guitar_signal)/sr2))
Guitar Waveplot¶
librosa.display.waveplot(guitar_signal, sr=sr2)

Guitar Track Audio¶
IPython.display.Audio(guitar_signal,rate=sr2)
Combine the Drum and Guitar Signals¶
combined_signal = drum_signal + guitar_signal
combined_signal[0] = 1
IPython.display.Audio(combined_signal, rate=sr1)
Combined Audio Waveplot¶
librosa.display.waveplot(combined_signal, sr=sr2)

Conclusion¶
The librosa library makes it fairly simple to manipulate the audio data. The audio data is a lot simpler than I had previously assumed, and the fact that all you need to keep track of are discrete amplitude values as integers and the rate at which the amplitude values are taken. There are many more manipulations that can be made with librosa, but I think we've met the goal of this specific blog as to just handle the audio data. The next step will be to use the data for some ol' machine learnin'.